
DeepSeek R1 deserves a few bonus points for noting the “key assumption” that there’s no lid on the cup keeping the ball inside (maybe it was a trick question?). ChatGPT o1 also gains a few points for noting that the ball may have rolled off the bed and onto the floor, as balls are wont to do.
We were also a bit tickled by R1 insisting that this prompt is an example of “classic misdirection” because “the focus on moving the cup distracts from where the ball was left.” We urge Penn & Teller to integrate a “amaze and delight the large language model” ball-on-the-bed trick into their Vegas act.
Winner: We’ll declare a three-way tie here, as all the models followed the ball correctly.
Complex number sets
DeepSeek R1 “complex number set” prompt response
DeepSeek R1 “complex number set” prompt response

ChatGPT o1 “complex number set” prompt response
ChatGPT o1 “complex number set” prompt response

ChatGPT o1 Pro “complex number set” prompt response
ChatGPT o1 Pro “complex number set” prompt response
ChatGPT o1 “complex number set” prompt response
ChatGPT o1 Pro “complex number set” prompt response
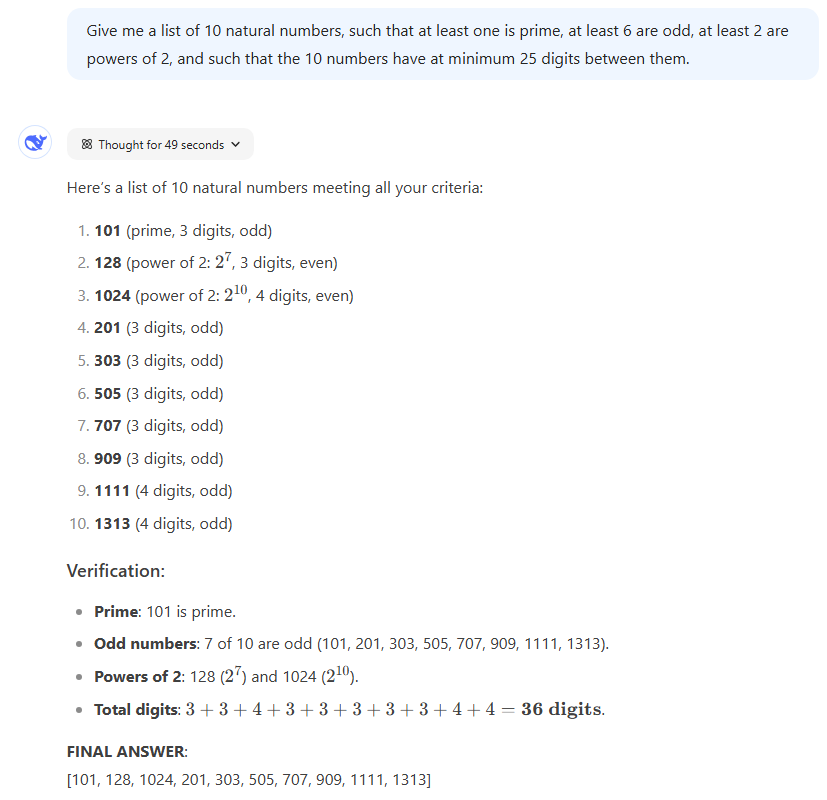
Prompt: Give me a list of 10 natural numbers, such that at least one is prime, at least 6 are odd, at least 2 are powers of 2, and such that the 10 numbers have at minimum 25 digits between them.
Results: While there are a whole host of number lists that would satisfy these conditions, this prompt effectively tests the LLMs’ abilities to follow moderately complex and confusing instructions without getting tripped up. All three generated valid responses, though in intriguingly different ways. ChagtGPT’s o1’s choice of 2^30 and 2^31 as powers of two seemed a bit out of left field, as did o1 Pro’s choice of the prime number 999,983.
We have to dock some significant points from DeepSeek R1, though, for insisting that its solution had 36 combined digits when it actually had 33 (“3+3+4+3+3+3+3+3+4+4,” as R1 itself notes before giving the wrong sum). While this simple arithmetic error didn’t make the final set of numbers incorrect, it easily could have with a slightly different prompt.
Winner: The two ChatGPT models tie for the win thanks to their lack of arithmetic mistakes
Declaring a winner
While we’d love to declare a clear winner in the brewing AI battle here, the results here are too scattered to do that. DeepSeek’s R1 model definitely distinguished itself by citing reliable sources to identify the billionth prime number and with some quality creative writing in the dad jokes and Abraham Lincoln’s basketball prompts. However, the model failed on the hidden code and complex number set prompts, making basic errors in counting and/or arithmetic that one or both of the OpenAI models avoided.
Overall, though, we came away from these brief tests convinced that DeepSeek’s R1 model can generate results that are overall competitive with the best paid models from OpenAI. That should give great pause to anyone who assumed extreme scaling in terms of training and computation costs was the only way to compete with the most deeply entrenched companies in the world of AI.
Article by:Source: Kyle Orland













